
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 프로그래밍언어론
- 다이어리
- 42seoul
- jenkins
- sql
- javascript
- 소켓
- 오블완
- 스프링부트 웹 소켓
- CI
- IOS
- 스프링부트
- springboot
- 아이패드다이어리
- CD
- 티스토리챌린지
- libasm
- 인공지능
- 오라클
- DBMS
- MySQL
- 스프링
- 데이터베이스
- swift
- 리눅스
- 네트워크
- AI
- JPA
- Xcode
- Spring
- Today
- Total
Hi yoahn 개발블로그
#8 제약조건, 인덱스, 뷰, 서브쿼리 본문
7장. CONSTRAINT 제약조건
1. 제약조건
1) 제약조건이란?
- 테이블에 올바른 데이터만 입력받고 잘못된 데이터는 들어오지 못하도록 컬럼마다 정하는 규칙을 의미
제약 조건의 종류
| 조건 이름 | 의미 |
| NOT NULL | 해당 컬럼은 NULL 값이 입력될 수 없다. |
| UNIQUE | 중복된 값이 입력될 수 없다 |
| PRIMARY KEY | ★ 테이블당 한 개만 설정 가능 |
| FOREIGN KEY | 다른 테이블의 컬럼을 참조해서 검사 |
| CHECK | 이 조건에서 설정된 값만 입력 허용, 나머지는 거부 |
2) 외래키란?
두 개의 테이블을 서로 참조하도록 설정됨
- 자식테이블이 부모 테이블에 있는 특정 컬럼을 참조하는 것
- 자식 테이블에서 참조하는 부모테이블의 컬럼은 참조키라고 한다.
- 참조하려는 컬럼은 unique
- 부모에 없는 값을 입력하려고 하면 ERROR
참조관계가 유지되도록 DBMS가 관리함 -> 부하
- 자식 테이블에 데이터 1개를 입력하는 경우
-> 부모 테이블의 데이터 N 개를 조사함
- 부모 테이블 참조키에서 값을 1개 삭제하는 경우
-> 자식 테이블의 N개 행을 조사해서 해당 값을 처리함
1.1 제약조건 사용하기
1) 테이블 생성 시 지정
CREATE TABLE new_emp1 (
no number(4) CONSTRAINT emp1_no_pk PRIMARY KEY,
--컬럼명 DataType CONSTRAINT 제약조건_이름 제약조건
name varchar2(20) CONSTRAINT emp1_name_nn NOT NULL,
jumin VARCHAR2(13)
CONSTRAINT emp1_jumin_nn NOT NULL
CONSTARINT emp1_jumin_uk UNIQUE,
loc_code NUMBER(1) CONSTRAINT emp1_area_ck CHECK(loc_code <5),
--외래키
deptno VARCHAR2(6) CONSTRAINT emp1_deptno_fk REFERENCES dept2(dcode)
);- < CONSTRAINT 제약조건_이름 > 이 부분을 생략하고 제약조건을 지정할 수도 있다.
이 경우, 오라클이 제약조건 이름을 자동으로 결정해서 찾기가 힘들다.
2) 제약조건 추가하는 방법
UNIQUE 제약조건 추가
ALTER TABLE _ ADD CONSTRAINT _
ALTER TABLE new_emp2 ADD CONSTRAINT emp2_name_uk UNIQUE(name);
NULL / NOT NULL 제약조건 추가하기
MODIFY
ALTER TABLE new_emp2 MODIFY (loc_code CONSTRAINT emp2_loccode_nn NOT NULL);
- NOT NULL 제약조건을 추가하는 것은 기본값으로 허용된 NULL을 NOT NULL로 변경하는 것이기 때문에 MODIFY, 수정하는 것
외래키 제약조건 설정하기
ALTER TABLE 테이블명
ADD CONSTRAINT 제약조건명 FOREIGN KEY(컬럼) REFERENCES 부모테이블(참조할 컬럼);
ALTER TABLE new_emp2 ADD CONSTRAINT emp2_no_fk FOREIGN KEY(no) -- (외래키로 지정할 컬럼) REFERENCES emp2(empno); -- 부모테이블 ( 참조할 컬럼 )
★ 참조할 컬럼에 UNIQUE 제약조건이 없으면 에러가 난다. (PRIMARY KEY | UNIQUE (-> INDEX 존재)둘중 하나여야 함)
(즉, 부모 테이블 쪽에 참조할 컬럼에 INDEX가 존재해야 한다)
- 부모 테이블 데이터를 지우려고 할 경우 -> 자식이 참조하고 있으므로 지울 수 없다
> 해결책
alter table c_test1 add constraint ctest1_deptno_fk foreign key(deptno) references c_test2(no) on delete cascade;
1) ON DELETE CASCADE;
부모 테이블의 데이터가 지워지면 자식테이블의 해당 데이터를 가진 행이 삭제됨
ALTER TABLE c_test1 ADD CONTRAINT ctest1_deptno_fk FOREIGN KEY(deptno) REFERENCES c_test2(no) ON DELETE SET NULL;
2) ON DELETE SET NULL
부모테이블의 데이터가 지워지면 자식테이블에서 해당 데이터가 NULL이 된다.
- 자식테이블의 외래키 컬럼이 NOT NULL로 지정된 경우 부모 테이블의 컬럼을 삭제하려하면 에러 남
> 외래키 제약조건 제거
ALTER TABLE 테이블명 DROP CONSTRAINT 제약조건명;
ALTER TABLE c_test1 DROP CONSTRAINT ctest1_deptno_fk;
- 테이블에 이미 NULL 값이 있는 경우, 해당 컬럼에 NOT NULL 옵션을 지정할 수 없다.
- 자식 테이블 컬럼에 NOT NULL 이 설정된 상태에서 외래키가 ON DELETE SET NULL이면 부모테이블을 삭제할 수 없다
(부모 테이블을 지우면 자식 테이블 컬럼이 NULL 이 되는데 이는 제약조건 위반)
ON DELETE SET NULL & NOT NULL -> 주의해서 사용
1.2 제약조건 관리하기
1) 제약조건 DISABLE 하기
(1) DISABLE NOVALIDATE 사용하기 - DEFAULT
ALTER TABLE 테이블명 DISABLE NOVALIDATE CONSTRAINT 제약조건명;
- 제약조건을 끈 다음부터는 입력되는 데이터에 대해서 제약조건에 대한 검사를 하지 않으므로 중복된 값도 삽입 가능
- 해당 제약 조건이 없어서 모든 데이터 수용 가능
(2) DISABLE VALIDATE
ALTER TABLE 테이블명 DISABLE VALIDATE CONSTRAINT 제약조건명;
- 제약조건은 DISABLE 했지만 제약조건 검사는 한다. 검증은 유효
- 해당 컬럼의 데이터 뿐만 아니라 테이블을 변경할 수 없게 하는 옵션
- DML 작업이 불가능함
DISABLE 의 기본 옵션은 NOVALIDATE
2) 제약조건 ENABLE 하기
(1) ENABLE NOVALIDATE
ALTER TABLE 테이블명 ENABLE NOVALIDATE CONSTRAINT 제약조건명;
- 이전에 들어있던 테이블의 내용은 검사하지 않고 ENABLE 후 입력되는 데이터만 제약조건 검사
(2) ENABLE VALIDATE - DEFAULT
ALTER TABLE 테이블명 ENABLE VALIDATE CONSTRAINT 제약조건명;
- 테이블에 들어있던 내용&이후에 입력되는 내용에 대해 제약조건 적용
- 테이블 데이터 전체 재검사
- 테이블에 제약조건을 만족하지 않는 행이 있으면 에러
3) EXCEPTIONS 테이블 사용하여 ENABLE VALIDATE 하기
- ENABLE VALIDATE 하는 과정에서 예외가 발생하면 EXCEPTIONS 테이블로 에러 별도 기록
ALTER TABLE 테이블명 ENABLE VALIDATE CONSTRAINT 제약조건이름 EXCEPTIONS INTO EXCEPTIONS; SELECT rowid, name from 테이블명 where rowid in (select row_id from exceptions);
4) 제약조건 조회
select owner, constraint_name, constraint_type, status
from user_constraints
where table_name='NEW_EMP2'; -- 테이블 이름 대문자로
- user_constraints: 제약조건에 대한 정보 테이블
select owner, constraint_name, table_name, column_name
from user_cons_columns
where table_name='EMP';
- user_cons_columns: 제약조건에 대해 오라클에서 쌓이는 테이블
5) 제약조건 삭제하기
ALTER TABLE 테이블명
DROP CONSTRAINT 제약조건이름;
2. 인덱스
- UNIQUE, PRIMARY KEY 제약조건 -> 인덱스가 생성됨
1) 사용자가 SELECT 문 수행
2) 오라클이 쿼리를 수행해서 데이터 출력
-1 메모리(데이터베이스 버퍼 캐시)에 해당 데이터가 있는지 확인
-2 (램에 없으면) 하드 디스크에 있는 데이터 파일에서 A의 정보가 들어있는 블록을 찾아서 램으로 복사해 온 후 사용자에게 값을 돌려줌
- 메모리 용량에 한계 -> 많이 사용되는 데이터는 램에 보관해두고 사용되지 않는 데이터는 디스크에 저장, 필요할 때 불러옴
- 하드디스크에 데이터가 너무 많을 경우, 사용자가 원하는 데이터를 찾기 위해 모든 블록을 다 읽어서 확인해야 함
== Table Full Scan (시간이 오래 걸린다.)
2.1 인덱스
: 데이터의 주소록을 만드는 것, 데이터의 주소 값을 가지고 있는 것이다.
- 인덱스가 있으면 모든 블록을 다 읽지 않고 원하는 데이터가 있는 블록의 주소를 바로 찾을 수 있고,
찾은 그 블록만 메모리로 복사하면 작업을 빨리 끝낼 수 있다.
인덱스 생성 명령
1. 해당 테이블의 내용을 전부 다 읽어서 메모리로 가져옴 (인덱스 생성하는 동안 데이터 변경 불가)
2. PGA 영역을 이용해서 해당 데이터들을 정렬
3. 정렬 후 인덱스 FILE 블록에 순서대로 기록
* 전체 테이블 스캔 -> 정렬 -> 인덱스 파일 블록에 기록
2.2 인덱스 작동 원리
B-Tree 인덱스
실제 데이터 -> 데이터 파일에 저장
인덱스 정보 -> 인덱스 파일에 저장

1. 인덱스에서 A라는 키 값을 조사
- 램에 데이터가 있으면 바로 보냄
- 램에 없으면 하드디스크의 Data File 에 가서 해당 데이터를 램으로 가져온 후 사용자에게 보냄
1) 인덱스에서 Root 블록을 램으로 가져와서 A 찾음 -> 7번 블록에 존재
2) 인덱스 파일에서 7번 블록을 다시 램으로 가져와서 A 가 들어있는 블록을 조사 -> 1번 블록
3) 인덱스 파일의 1번 블록을 다시 램으로 복사 -> 데이터 파일에서 A가 어떤 블록에 들어있는지 찾는다.
4) A-1, B-1 -> 데이터 파일의 실제 블록 정보
- 데이터 파일에 1번 블록을 램으로 복사해서 A를 찾아 사용자에게 줌
(이 블록에는 A, B의 행이 같이 저장되어 있음)
2.3 인덱스 종류
1) B-TREE 인덱스
balanced Tree
- 데이터가 아무리 많아도 O(logN) 의 탐색시간 (삽입/삭제/조회 시간 모두 O(logN)
- data의 삽입/삭제가 발생해도 균형을 유지
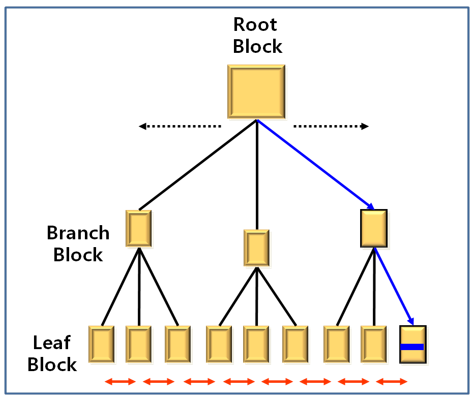
- 모든 키 값(데이터 블록의 주소)은 다 Leaf 블록에 존재함
- 탐색할 때는 Root 블록부터 어느 leaf 노드에 있는지를 탐색하는게 목적
- 각각의 블록에 존재하는 키 값을 비교해서 어느 노드로 갈지 정해서 Leaf 블록에 도달하면 해당 데이터의 rowid를 찾은 후 데이터가 들어있는 블록을 메모리로 복사
(1) UNIQUE INDEX
: 인덱스를 만드는 (컬럼)키 값에 중복되는 데이터가 없다
생성 문법
CREATE UNIQUE INDEX 인덱스명 ON 테이블명(컬럼명1 ASC|DESC, 컬럼명,,,);
- B-TREE 인덱스 + UNIQUE 제약조건
- 속도가 빠름
- 인덱스가 제약조건과 유사하게 동작
(2) NON-UNIQUE INDEX
: 중복되는 데이터가 들어가는 경우
CREATE INDEX 인덱스명 ON 테이블명(컬럼명1 ASC|DESC, 컬럼명2,,,);
(3) Function Based 인덱스(함수기반 인덱스)
- 인덱스는 조건 컬럼 / 조인 컬럼에 만들어야 한다.
CREATE INDEX 인덱스명 ON 테이블명(컬럼 조건식PAY + 1000)
원래 pay+1000이라는 컬럼이 없지만 함수처럼 연산을 해서 인덱스를 만들어 줌
INDEX Suppressing Error
- 생성한 인덱스를 사용하지 않게 되는 것
- where 조건절에서 pay +1000 =2000 으로 조회하면 인덱스가 작동하지 않는다.
★ 인덱스를 사용하려면 WHERE절의 조건을 다른 형태로 가공해서 사용하면 안된다.
(4) DESCENDING INDEX(내림차순 인덱스)
- function based index 기반
- 내림차순으로 인덱스를 생성하는 것
CREATE INDEX 인덱스명 ON 테이블명(컬럼 DESC);
(5) 결합 인덱스
CREATE INDEX 인덱스명 ON 테이블명(컬럼1, 컬럼2);
- 두 개 이상의 컬럼을 묶어서 하나의 인덱스 생성
- WHERE 절 조건식에서 두 컬럼을 동시에 AND 조건으로 조회할 때 큰 장점
- OR 조건으로 연결할 때는 결합 인덱스가 작동하지 않는다.
- 결합인덱스가 생성된 컬럼의 순서를 판단하여 WHERE 조건의 조건식을 기술하면 최적화할 수 있다.
(두개의 컬럼을 합쳐 결합인덱스 키 생성 -> 해당 데이터 찾을 때 두개의 컬럼을 동시에 만족하는 블록을 검색)
*컬럼의 순서가 중요
- 첫번째 조건에서 최대한 많은 데이터를 걸러서 두번째 검사를 쉽게 만들어 줘야 함
2) BITMAP INDEX
B-TREE INDEX: 데이터 값의 종류가 많고 중복데이터가 적을 경우 사용하는 인덱스
- 컬럼 값 별로 각각 비트맵 생성

성별 컬럼에 값이 M, F 두가지이므로 각 행이 그 값을 가지는지 아닌지를 1,0으로 표시
-> 비트를 보면 그 컬럼이 M/F인지 구분할 수 있다.
- 데이터 값의 종류가 적고 동일한 데이터가 많을 경우에는 주로 BITMAP 인덱스 사용
* 컬럼 값의 종류 수 만큼 비트맵이 생성됨
< 주의 사항 >
- 행의 카디널리티가 작아야 함
- 해당 컬럼값이 변경되거나 추가되면 기존 비트맵을 전부 다 고쳐야 함
-> 데이터가 자주 변경되는 경우 사용하지 않는 것이 좋다
- Bit 연산을 통해 빠르게 행을 조회할 수 있다.
(이미 만들어진 테이블을 빠르게 조회해서 분석)
- 데이터가 변경될 때 모든 맵에 변경된 데이터를 반영해야 함 (그 행에 컬럼 값 어떤 것이 들어있는지, 안들어있는지)
2.4 인덱스의 주의사항
1) DML에 취약
(1) INDEX Split 현상
- 인덱스가 생성되어 있는 컬럼에 새로운 데이터가 삽입되는 경우
-> INDEX Split 현상이 발생한다.
? INDEX Split 현상
- 키를 추가해야 하는데 leaf 블록이 꽉 차있는 경우 블록을 반으로 쪼개서 인덱스 구조를 바꿈
- 절반은 왼쪽, 절반은 오른쪽으로 나눠서 보내야 함
=> 밸런스를 유지하기 위한 것, 블록에 공간이 있으면 split 현상이 발생하지 않을 수 있다.
(2) DELETE -> INDEX 파일의 데이터는 지워지지 않음
- 속도 때문에 INDEX는 DELETE 하지 않음
- 데이터 테이블에서 행을 삭제해도 인덱스에서는 지워지지 않음
- 인덱스 키 값은 사용하지 않는다고 표시하고 계속 진행
(3) UPDATE - DELETE & INSERT 현상
- 인덱스에서는 DELETE가 먼저 이루어진 후 새로운 데이터를 INSERT
- 두 작업이 동시에 일어남 -> 부하
2) 다른 SQL 실행에 악영향을 줄 수 있다.
- DBMS 최적화 차원에서 어떤 쿼리는 인덱스를 사용해서 진행되도록 정보가 셋팅될 수 있는데 신규 인덱스를 추가한 경우, DBMS 최적화에서 신규 인덱스를 사용해보려고 검토할 수 있다.
-> 기존에 잘 사용하고 있는 것을 사용하지 않게 될 수 있다.
2.5 인덱스 관리 방법
1) 인덱스 조회하기
테이블 -> USER_IND_COLUMNS, USER_INDEXES
2) 사용 여부 모니터링하기
- 모니터링 시작
ALTER TABLE INDEX IDX_EMP_ENAME MONITORING USAGE;
- 모니터링 중단
ALTER TABLE INDEX IDX_EMP_ENAME NOMONITORING USAGE;
- 사용 유무 확인 - 어떤 인덱스가 사용되었는지 확인할 때
SELECT index_name, used
FROM v$object_usage
WHERE index_name = 'IDX_EMP_ENAME';
3) INDEX Rebuild 하기
- DML 작업 -> 인덱스의 밸런싱 상태를 흩트려서 성능에 나쁜 영향
- 주기적으로 점검해서 밸런싱 상태 유지
- index는 추가만 되고 삭제는 안됨
-- 상태 조회 analyze index idx_inxtest_no validate structure; --<데이터 삽입 생략 -- 상태조회 select (del_lf_rows_len / lf_rows_len) *100 balance -- 값이 커질수록 인덱스가 비효율적인 것 from index_stats where name='IDX_INXTEST_NO'; --데이터 삭제 후 인덱스 조회 delete from inx_test where no between 1 and 4000; -- 수동으로 analyze 실행해야 함 select count(*) from inx_test; --rebuild alter index idx_inxtest_no rebuild; -- 리빌드 후 balance -> 0
2.6 Invisible Index
- 불필요한 인덱스가 있다면 없애는게 효율이 좋다.
- 삭제하기 전에 실제로 사용하지 않는 인덱스인지 알아보기 위해 사용
- 인덱스를 없애지는 않고 사용되지 않게 함
-> 문제가 발생하면 다시 visible 로 바꿈
* 옵티마이저 입장에서 사용하지 않는 것, 안보이게 하는 것이다.
-> 사용자는 볼 수 있음, DML 작업 시 인덱스에 대한 변경은 계속 반영됨
- 최적화 수행기가 인덱스를 사용하느냐 안하느냐의 차이
-- 인덱스 INVISIBLE로 변경하기 ALTER INDEX 인덱스명 INVISIBLE; -- 인덱스 VISIBLE로 변경 ALTER INDEX 인덱스명 VISIBLE;
1) 인덱스를 활용하여 정렬한 효과를 내는 방법
- 인덱스는 정렬이 되어있기 때문에 테이블에서 데이터를 가져올 때 인덱스를 활용해서 가져오면 정렬된 상태로 출력된다.
* 인덱스가 있는 컬럼만 가져오기
* 인덱스가 걸린 컬럼을 조건으로 사용(더미 조건)
2) 최소/최대값 구하기
SELECT NAME FROM EMP4
WHERE name >'0' and ROWNUM=1;
- 이미 정렬되어 있으므로 첫번째 행만 가져오고 끝 (최소값)
ROWID를 조회할 수 있다.
- 실제 테이블에는 없지만 오라클이 안보이는 영역에 저장해 둔것
- rowid = DBMS가 관리하는 식별정보를 결합해 둔 것,
특정 행에 대한 물리적인 위치 식별자를 담고 있다.
INDEX
- 보통 index를 사용하면 퍼포먼스가 올라간다.
- 저하할 수 도 있으므로 쿼리 실행 계획, 수행 속도를 모니터링할 필요성 있음
- data가 큰 경우 index를 걸어주는게 좋다
- 모든 컬럼들을 다 엮어서 일반적인 인덱스나 결합 인덱스를 만드는 것 보다는
내가 사용하는 목적 측면에서,
where 절에서 어떤 컬럼들에 조건식을 많이 쓰는지를 보고 해당 컬럼에 인덱스를 걸어 퍼포먼스를 높일 수 있는 방식으로 접근
3. 뷰 VIEW
뷰의 목적
1) 보안
원본 테이블을 오픈하면 일반 사람들이 다 접근할 수 있다.
뷰를 사용하여 일부 정보들을 가릴 수 있다.
2) 편의성
여러가지 테이블을 조인하여 작업하는 일이 많을 때 그 쿼리를 뷰로 만들어두고 필요할 때마다 불러서 사용하면 편하다.
VIEW
- 가상의 테이블
- 뷰에 물리적으로 행들이 저장되는 것은 아님
- 원본테이블을 바라보는 것
- 원본테이블에서 특정 컬럼/행 을 필터링해서 뷰를 만듦
-> 사용자는 테이블을 조회하는 것이 아니라 뷰를 조회해서 작업을 수행하게 됨
뷰에 DML 권한이 있으면 데이터 수정/업데이트 시 원본 테이블에 반영됨
-> 보통 조회 용도로 사용
3.1 단순 뷰
- 조인 조건이 없는 것
- VIEW를 생성할 서브쿼리에 조인 조건이 안들어가고 1개의 테이블로 만들어지는 간단한 뷰
- 뷰를 생성하려면 CREATE VIEW 권한이 필요함
1) 일반 단순 뷰 생성하기
-- 일반 단순 뷰 생성하기
CREATE OR REPLACE VIEW v_emp1
AS
SELECT empno, ename, hiredate
FROM emp;
select * from emp1;★일반적인 뷰는 인덱스 생성 불가
2) 뷰를 통해 데이터 변경
(1) VIEW에 DML 작업 수행
INSERT INTO 뷰 VALUES(값1, 값2);
- 뷰를 통한 DML 작업이 일반 테이블에 수행하는 것과 동일하게 작동
(2) With Read Only 테스트 --읽기 전용 뷰 생성
CREATE VIEW 뷰이름
AS
SELECT a, b
FROM 테이블명
with read only; -- 읽기 전용 뷰로 생성- 읽기 전용 뷰에서는 DML 작업을 수행할 수 없다.
- 같은 테이블에 대한 다른 뷰로 DML작업을 수행하면 읽기 전용 뷰에도 반영된다.
(3) With Check Option
CREATE VIEW view3
AS
SELECT a, b
FROM o_table
WHERE a=3
WITH CHECK OPTION;- 위에서 a=3인 데이터를 가져오면서 with check option 을 사용함
-> a=3이 아닌 다른 값으로 변경하려하면 에러
-> a컬럼이 아닌 컬럼은 변경 가능 ( b는 제약 조건과 상관없는 컬럼이므로)
★ 뷰의 단점 : 성능저하를 일으킬 수 있다.
장점 : 보안, 편의성
- 모든 뷰는 view에 대해 select 를 실행하면 view를 생성할 때 정의했던 서브쿼리가 수행되어 그 결과가 되돌려진다.
3.2 복합 뷰
- 뷰 생성 시에 여러 테이블의 조인이 관여되어 있으면 복합뷰라고 한다
SELECT OR REPLACE VIEW v_emp
AS
SELECT e.ename, d.dname
FROM emp e, dept d
WHERE e.deptno = d.deptno;- 복합뷰를 생성하여 한 컬럼만 조회하는 경우, view에 대한 select는 view 에 대한 서브쿼리가 통째로 수행되므로 성능 저하의 원인
3.3 Inline View
테이블이 들어갈 자리에 뷰의 서브쿼리를 대신 넣어주는 것
- 뷰를 생성하면 메모리에 서브쿼리의 내용이 담겨서 유지됨
- 인라인 뷰는 메모리에 임시로 생성해서 돌아가게 된다.
--emp 테이블과 dept 테이블을 조회하여 부서 번호와 부서별 최대 급여, 부서명을 출력
SELECT e.deptno, d.dname, e.sal
FROM (SELECT deptno, MAX(sal)
FROM emp
GROUP BY deptno) e, dept d
WHERE e.deptno=d.deptno;3.4 VIEW 조회 및 삭제
SELECT view_name, text, read_only
from user_views;
- 존재하는 뷰를 조회
1) 뷰 삭제
DROP VIEW 뷰이름;
3.5 Materialized View (MView, 구체화된 뷰)
- 일반 뷰
각 유저가 뷰를 조회할 때마다 10억건의 데이터를 조회하는 서브쿼리가 수행됨
-> 원본 테이블의 사이즈가 크면 부담
- 일반 뷰는 테이블에 있는 서브쿼리를 실행시키는 역할로 데이터를 가지고 있지 않음
★ Mview
독자적으로 하나 생성됨
-> 테이블과 거의 동일한 기능을 함
* 최초 Mview를 만들 때 서브쿼리를 통해 내용을 채움 (실제 데이터 가지고 있음)
-> 이후 조회 시에는 서브쿼리를 통해 가져온 데이터만 조회함
Mview를 생성하기 위한 권한
- QUERY REWRITE
- CREATE MATERIALIZED VIEW
1) Mview 생성
CREATE MATERIALIZED VIEW 뷰이름
--옵션
AS
SELECT profno, name, pay
FROM professor;- 인덱스 생성 가능
- 원본테이블에 인덱스가 존재하는 경우 그 인덱스를 Mview에도 만들어줌
2) Mview 관리
원본 테이블에서 한 행을 삭제해도 Mview에서는 삭제되지 않음
-> 데이터를 따로 저장하고 있어서, 사용자가 요청해야 동기화 해줌
BEGIN
DBMS_MVIEW.REFRESH('M_PROF');
END;
/- Mview 조회
select mview_name, query
from user_mviews
where mview_name='M_PROF';
- Mview 삭제
DROP materialized view m_prof;
4. Sub Query 서브쿼리
서브쿼리: 임시적으로 쓸 조회 결과를 만들어서 현재 개발할 sql코드의 일부로 사용
-> 코드의 간결화, 효율성을 목적으로 함
- 서브쿼리는 where 절에 연산자 오른쪽에 위치해야 함
- 반드시 괄호로 묶어야 함
- order by 절이 올 수 없다.
만들어진 서브쿼리는 메모리에 상주
-> 이후 동일한 내용을 반복하게 되면 메모리에 있는 것을 가져와서 빠르게 수행
- 일반적인 join은 물리 디스크에 있는 테이블에서 쿼리를 반복해서 가져옴
- 서브쿼리 = 메모리에 저장되어 있음
- 물리 메모리의 범위에서 서브쿼리 결과물이 메모리에 상주 -> 그것을 재활용하여 빠른 속도
1) 단일행 서브쿼리
| 연산자 |
| = , <>, > , >= , < , <= |
where 절에서 서브쿼리를 통해 원하는 값을 먼저 찾고, 찾은 값과 컬럼을 비교하여 조건을 만족하는 행들을 출력
2) 다중 행 서브쿼리
| 연산자 | 의미 |
| IN | 서브 쿼리 결과와 같은 값을 찾는다 |
| EXISTS | 서브 쿼리 값이 있는 경우 메인 쿼리를 수행 (비교 X) |
| >ANY | 서브 쿼리 결과 중 최솟값 (하나보다 크면 OK) |
| <ANY | 서브 쿼리 결과 중 최댓값 |
| <ALL | 서브쿼리 결과 중 최솟값 |
| >ALL | 서브쿼리 결과 중 최댓값 |
** IN 연산자는 다중행 연산자, 내부적으로 DISTINCT 연산을 하여 중복을 제거
(IN 연산자 안에는 DISTINCT 사용 X)
** EXISTS : 존재 여부 확인, 하나라도 있으면 더이상 검색하지 않고 바로 빠져나옴
IN 연산자는
메인 쿼리의 테이블 사이즈가 크고, IN 연산자 앞의 컬럼에 인덱스가 존재할 때 (조건에 인덱스 존재할 때)
EXITST는
내부 쿼리 테이블 사이즈가 크고, 조사해야 할 컬럼에 인덱스 걸려있을 때
3) 다중 컬럼 서브쿼리
서브 쿼리 조회 결과 컬럼이 2개 이상
SELECT grade, name, weight
FROM student
WHERE ( grade, weight ) in (select grade, max(weight)
from student
group by grade)
order by 1;- 두개의 컬럼을 묶어서 모양 맞추기
4) 상호 연관 서브쿼리
- 메인 쿼리 값을 서브쿼리에서 참조하여 수행하고 그 결과를 다시 메인쿼리로 반환해서 수행
- 서로 데이터를 주고받는 형태
SELECT name, position, pay
from emp2 a
where pay >= (selet avg(pay) from emp2 b
where a.position = b.position );
5) 스칼라 서브쿼리
- select 절 내에 오는 서브쿼리
SELECT (서브쿼리 - 스칼라 서브쿼리)
FROM (서브쿼리 -> 인라인 뷰)
WHERE (서브쿼리)
스칼라 서브쿼리
- 한 번에 결과를 1행씩 반환
- 서브쿼리의 결과가 없을 경우 NULL 값을 돌려줌
- OUTER JOIN과 동일
- 한 행만 반환이 가능, 2건 이상의 데이터 요청 시 에러
- 스칼라 서브쿼리는 한 행, 한 컬럼이어야 에러가 발생하지 않음
스칼라 서브쿼리 성능을 빠르게 하려면
- 조인 컬럼에 인덱스가 있는게 좋다 -> FULL SCAN 의 위험을 낮춤
- 메인쿼리 결과가 100건 -> 스칼라 서브쿼리를 100번 호출
- 인덱스가 없으면 FULL SCAN을 100번 함
**서브 쿼리 결과물에 NULL 처리를 해야할 곳은 메인 쿼리이다.
null 을 넣는 곳은 메인 쿼리 -> 서브쿼리에서 nvl을 하면 적용 안되고 null 그대로 출력됨
**
with 테이블 AS
일종의 가상 테이블(뷰와 유사)
- 반복 수행되는 쿼리를 한번만 수행하여 결과를 메모리에 두고 재사용
- UNION 등에서 같은 내용 조회 등의 경우에 대체 가능
- sql 코딩 효율성 향상
- 이 가상 테이블이 최초 사용될 때 한번 서브쿼리를 조회해서 가상 테이블화 해놓고,
이후에 사용될 때는 재호출하지 않고, 최초에 호출된 내용을 계속 재활용
with a AS ( select 쿼리.. )[, b AS ( select 쿼리,, )] select * from a union all select * from b;
union을 여러번 하더라도 그 테이블을 가상 테이블로 만들어두었기 때문에 최초에 만들어 둔 것을 재활용함
inline 뷰 대신에 사용 가능
'데이터베이스 > Oracle' 카테고리의 다른 글
| #7 DML (insert, insert all, update, delete, update join, 트랜잭션) (0) | 2020.06.14 |
|---|---|
| #6 DDL 명령과 딕셔너리 (create, 임시 테이블, alter(컬럼 추가, 이름 변경, 크기조정, 삭제), truncate, delete (0) | 2020.06.11 |
| #5 JOIN (0) | 2020.06.08 |
| #4 복수행 함수 (0) | 2020.04.22 |
| #3 SQL 단일행 함수 (0) | 2020.04.21 |


